


ML data argument pattern
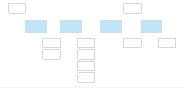
The argument pattern relating to this stage of the AMLAS process is shown in Figure 9 below. The key elements of the argument pattern are described below.
The top claim in this argument pattern is that the data used during the development and verification of the ML model is sufficient. This claim is made for all three sets of data used: development, test and verification ([N], [O], [P]). The argument sets out how the sufficiency of these datasets could be demonstrated. This provides confidence in the data used, and thus increases assurance of the model itself.
The argument strategy is to argue over the defined ML data requirements which are provided as context to the argument ([L]). To support this strategy two sub‐claims are provided in the argument, one demonstrating the sufficiency of the ML data requirements, and another to demonstrate that those defined data requirements are satisfied.
It is not possible to claim that the data alone can guarantee that the ML safety requirements will be satisfied, however, the data used must be sufficient to enable the model that is developed to do so. This is shown by demonstrating that the requirements defined for the ML data are sufficient to ensure it is possible to create an ML model that satisfies the ML safety requirements. The ML data requirements justification report ([M]) created in Activity 4 is explicitly provided to provide evidence for this.
It must be demonstrated that all of the data used throughout the lifecycle (development, test and verification) satisfies the defined ML data requirements. This is done in the context of the decisions made during data collection to ensure the data meets the requirements. These decisions are captured and explained in the data generation log ([Q]).
To show that the data requirements are satisfied, the strategy adopted is to argue over each type of data requirement (relevance, completeness etc). The types of data requirements that have been considered should be justified. This is done explicitly in J3.1.
For each type of data requirement, the ML data validation results ([S]) are used as evidence that each dataset meets the requirements.

